Unifying Textual Prompt and Reference Image for Context-Preserving Object Insertion
Given a background, a prompt and a reference image of the object, insert the object into the background at a reasonable location while preserving visual consistency.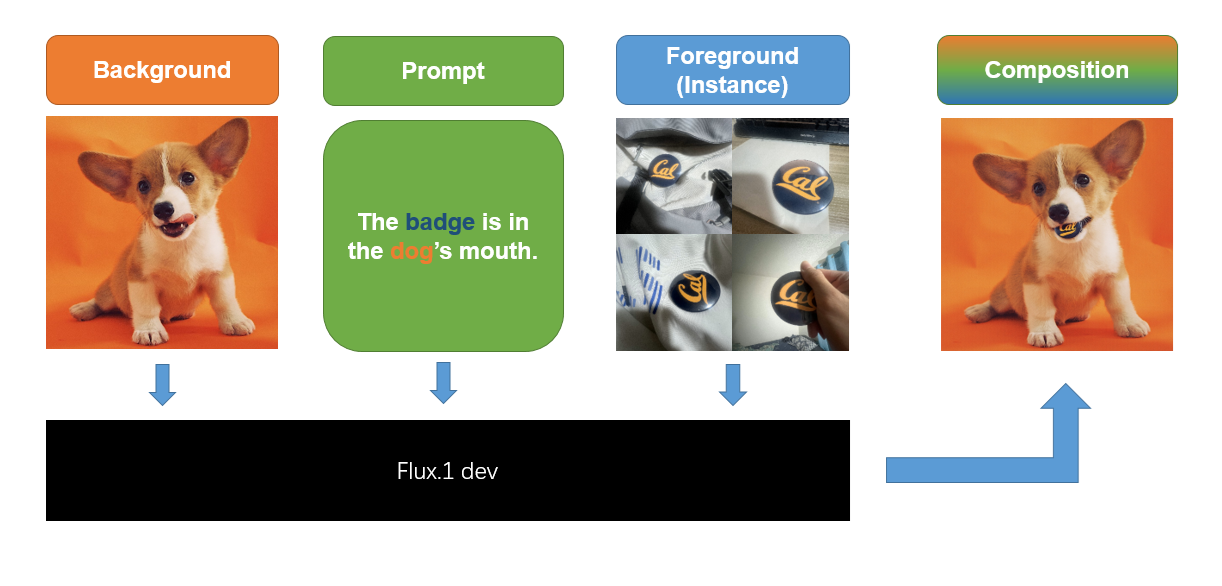

Given a background, a prompt and a reference image of the object, insert the object into the background at a reasonable location while preserving visual consistency.
We implemented MCTS and Tree of Thought to guide code synthesis based on execution feedback.
We implemented Dreambooth-LoRA and Text Inversion for style transfer based on Stable Diffusion v2.1.
We implemented a self-certainty guided R-MCTS method for web agents.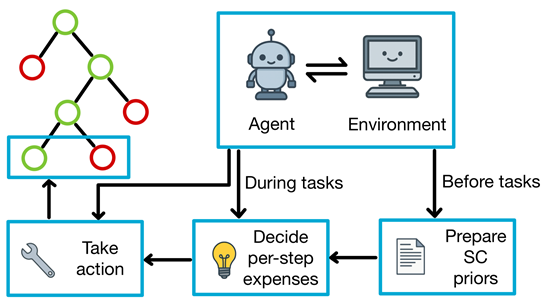
We built and trained retrievers across knowledge-agnostic domains for multi-choice question answering.